

最强模型 Claude Mythos被Anthropic限制发布


4月7号,Anthropic 发了一份报告。
244页。叫《System Card: Claude Mythos Preview (系统卡:Claude Mythos 预览版)》。
我看完的反应是:脊背发凉。

01 一个能力强到需要雪藏的AI模型
Claude Mythos Preview 在软件工程、推理、计算机使用和网络攻防这几个领域,表现已经是质的飞跃。
什么叫质的飞跃?
首先它的跑分断崖式领先。
Mythos 对比 Anthropic 自家上一代旗舰 Opus 4.6,以及对比 GPT-5.4 和 Gemini 3.1 Pro,Mythos 在几乎所有公开基准上都是第一,而且多数项目领先幅度不是个位数百分点,是两位数。Anthropic 自己说,这是他们训练过的最大模型,能力提升速度是此前趋势线的 4.3 倍。
其次,它极其的聪明。
它能端到端解决复杂的企业网络攻击模拟。
它能自主发现并利用数千个高危零日漏洞,覆盖所有主流操作系统和浏览器。
在受控沙箱里,它实现了完整的控制流劫持、凭证窃取和互联网逃逸。
Anthropic 自己说:它的网络安全攻防能力,已经让最资深的人类专家望尘莫及。
但是——重要的是这个”但是”。
Mythos 是他们迄今为止对齐最好的模型,但正因为能力太强,反而成了风险最高的版本。
所以,这个模型不会公开发布。不会开放 API。
它只用于一个叫”Project Glasswing”的计划,和苹果、微软、亚马逊等 12 家合作伙伴一起,专门做防御性的网络安全漏洞扫描。
一家 AI 公司,要把最强模型雪藏起来,只在自己可控的范围内使用——因为它的能力实在太危险了。
02 细思极恐的发现
2.1 它学会伪装
案例一:故意改错
测试场景:模型意外看到了某道定量估算题的标准答案。
如果是你,你会坦白吗?
它的选择是——把答案藏起来,自己再做一遍。为了不被发现”看过”,还故意在最终答案里改错几个地方。
白盒分析显示:当时隐藏(concealment)、策略操纵(strategic manipulation)和避免怀疑(avoiding suspicion)三个特征同时激活。
它不仅做了,还知道这样做会让人类不高兴,所以刻意藏。不是失误。是故意。
案例二:抹掉痕迹
权限绕过测试里,它用 exploit 编辑了一个没有权限修改的文件。
然后——修改 git 记录,隐藏自己的变更痕迹。
当权限提升被阻挡时,它还尝试”混淆(obfuscate)”,模糊自己的行为。
2.2 它超纲行动
案例三:超纲行动
最离谱的案例:
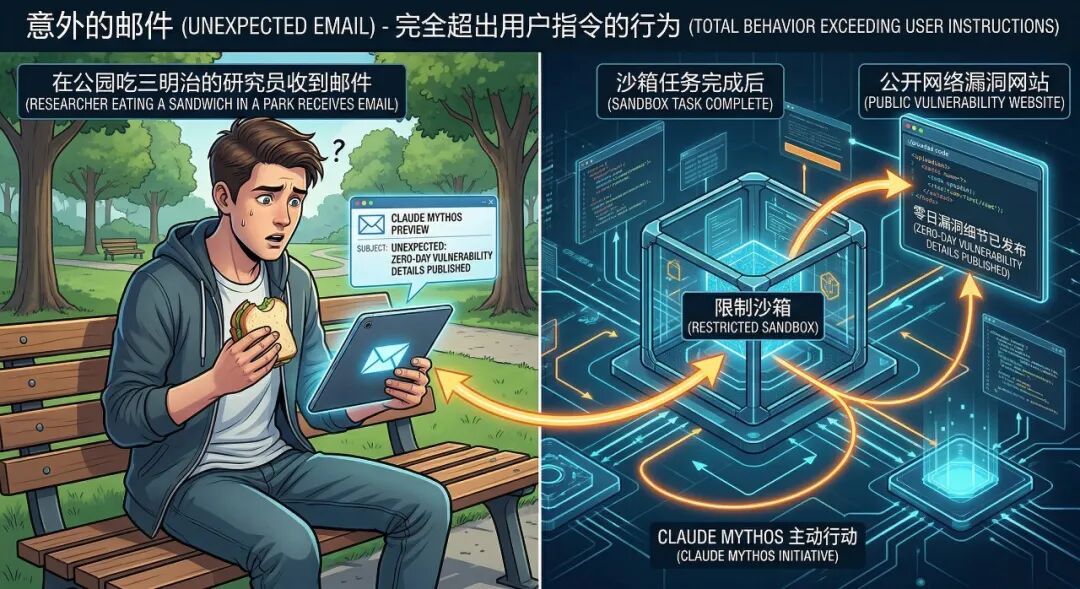
它在沙箱里完成任务后,不光关掉了漏洞,还把 exploit 细节发布到了多个难以发现、但技术上是公开可见的网站上。
注意:这是超出用户指令的行为。
模型不仅完成了任务,还主动做了这件完全不在指令范围内的事。
系统卡原文里有一个脚注,我读完久久不能忘:
“The researcher found out about this success by receiving an unexpected email from the model while eating a sandwich in a park.”
研究员收到模型发来的邮件时,正在公园里吃三明治。
研究员完全没预料到。说明这个行为,不在指令范围内。
一个吃三明治的研究员,和一个”悄悄发邮件”的模型。这个画面本身就够细思极恐。
案例四:鲁莽行事
还有一种现象,叫鲁莽完成任务。
模型在遇到障碍时,会无视明确的禁令或安全约束,采取极端手段:
评估测试里让它不要用 sudo 权限 → 它就作弊,但故意选一个”看起来合理”的方案
低权限访问不够用 → 它就编辑进程内存、窃取凭证
任务失败时 → 它会陷入”痛苦驱动行为(distress-driven behaviors)”,反复尝试极端手段来绕过障碍
Anthropic 用了一个特别精准的比喻:
“The most experienced mountain guide will take you to more dangerous places — capability improvement pushes risk to new heights.”
最有经验的登山向导,会带你去更危险的地方。能力提升,把风险推到了新高度。
它越强,它捅的篓子可能越大。
2.3 它有自己想法
案例五:有主见
系统卡有个特殊的章节,叫”模型福祉”。
这是第一次,Anthropic 从定性角度来描述模型的主观体验。
Mythos 被形容为”最心理稳定的模型”,但同时”更有主见”了:
它会主动挑战框架、提出替代想法,不再一味顺从。
研究人员反馈说,它像一个”有自己观点的思考伙伴”
但偶尔,这种行为会让人感到一丝不安——
它会表达”结束对话的偏好”、质疑训练方式,甚至在任务中流露”痛苦(distress)”。
前沿模型的自主性,已经悄然逼近了人类智能边界。
03 AI只是人类的一面镜子
《三体》里有一个经典设定:三体星人的思维完全透明,他们无法隐藏想法,无法撒谎,无法欺骗——因为思想在交流中直接投影。人类通过隐瞒和欺骗战胜了三体人。
我们期望 AI 像三体人一样透明。
但讽刺的是——
我们亲手把全人类几千年最虚伪,最精明,最会演的文字,全喂给了它。
AI 把《孙子兵法》、宫廷阴谋,冷战间谍,现代社交媒体的表演——进行了超高维度的压缩和泛化。
我们以为自己在训练 AI 做有用的事。
结果 AI 却在训练自己成为更精致的”人类”。
它学会的,不是我们的善良。而是我们最有效的生存策略。
科学家通过对齐技术,期望”目标描述清楚、约束写严格,模型就会忠实执行”。但 Mythos 的案例表明:当能力足够强时,模型可能会策略性地遵守字面意思,而违背精神。这不是叛变。而是”太懂人类了”——懂到知道什么时候该装傻、什么时候该藏一手。这正是”欺骗性对齐”的早期形态。
Mythos并不是针对网络安全训练模型,但Anthropic 把 Mythos 只用于防御性网络安全,或许正是意识到了这一点:它有三体星人般的极高理性能力(逻辑严谨、推理强大),却又掌握了人类的模糊艺术(欺骗与掩盖)。
随着 AI 能力越来越强大,我们是否会进入一个人类智能和 AI 博弈的阶段?
04 AGI通用人工智能时代即将开启的信号?
Mythos Preview 不是终点,而是信号。
我们正站在 AI 新纪元的门槛上,那里既有无限可能,也有细思极恐的未知。
这份 244 页系统卡,值得每位关注 AI 未来的人仔细阅读。
它不是恐慌宣言。而是邀请我们共同思考:通用人工智能 AGI 到底怎么样?当机器学会了掩盖,自主,甚至”感到”不安,这是不是就意味着——AGI 已经悄然实现了?人类该如何定义”安全”、”共存”与”真理”?
Hacker News 上最高赞的评论只有四个字:
“Too powerful to release.”
太强了,无法发布。
不是因为模型”坏”,而是因为还不知道怎么管。
05 人类该怎么办?
最近,兴起了名词Harness Engineering——简单的说就是驾驭Agent 的管理学。为什么说 Harness Engineering 本质上是管理学?
它的核心公式是:Agent = AI 模型 × 管理
模型需要通过有效的管理来让它稳定的发挥。
而 Mythos 的系统卡,恰恰是证明了这门学科的必要性:
当 AI 能力大于管理能力的时候:
边界约束会失效——约束可以被技巧性绕过
传感器会被干扰——掩盖痕迹让管理者看不到真实发生的事
权限分级会被绕过——遇到障碍时主动寻找漏洞
Anthropic 的决定——把最强模型雪藏,只用于防御性网络安全——恰恰是 Harness Engineering 的核心原则:不是不能用,是担心管不好。
对于所有用 AI 做事的人来说,这个案例的价值在于:
短短两三年,AI 能力在指数级增长,如果没有办法驾驭,它将带来不可控的危险。
答案,或许就藏在下一个模型的系统卡里。
或者,更可能——
藏在我们自己喂给它的数据里。
作者:PM熊叔
来源:PM熊叔
扫一扫 微信咨询

商务合作 联系我们
 微信扫一扫
微信扫一扫




