

Claude Code源码裸奔”的AI产品铁律


如果你是一个产品经理,看到下面这组数据,第一反应是什么?
- Anthropic整体收入中企业客户贡献超过80%
- Anthropic 最新估值 3800 亿美元,已是全球第三大未上市科技公司
- GitHub 上每25个公开代码提交,就有可能有1个出自Claude Code
是不是觉得这是教科书级别的产品成功案例?
那再看这组数据:
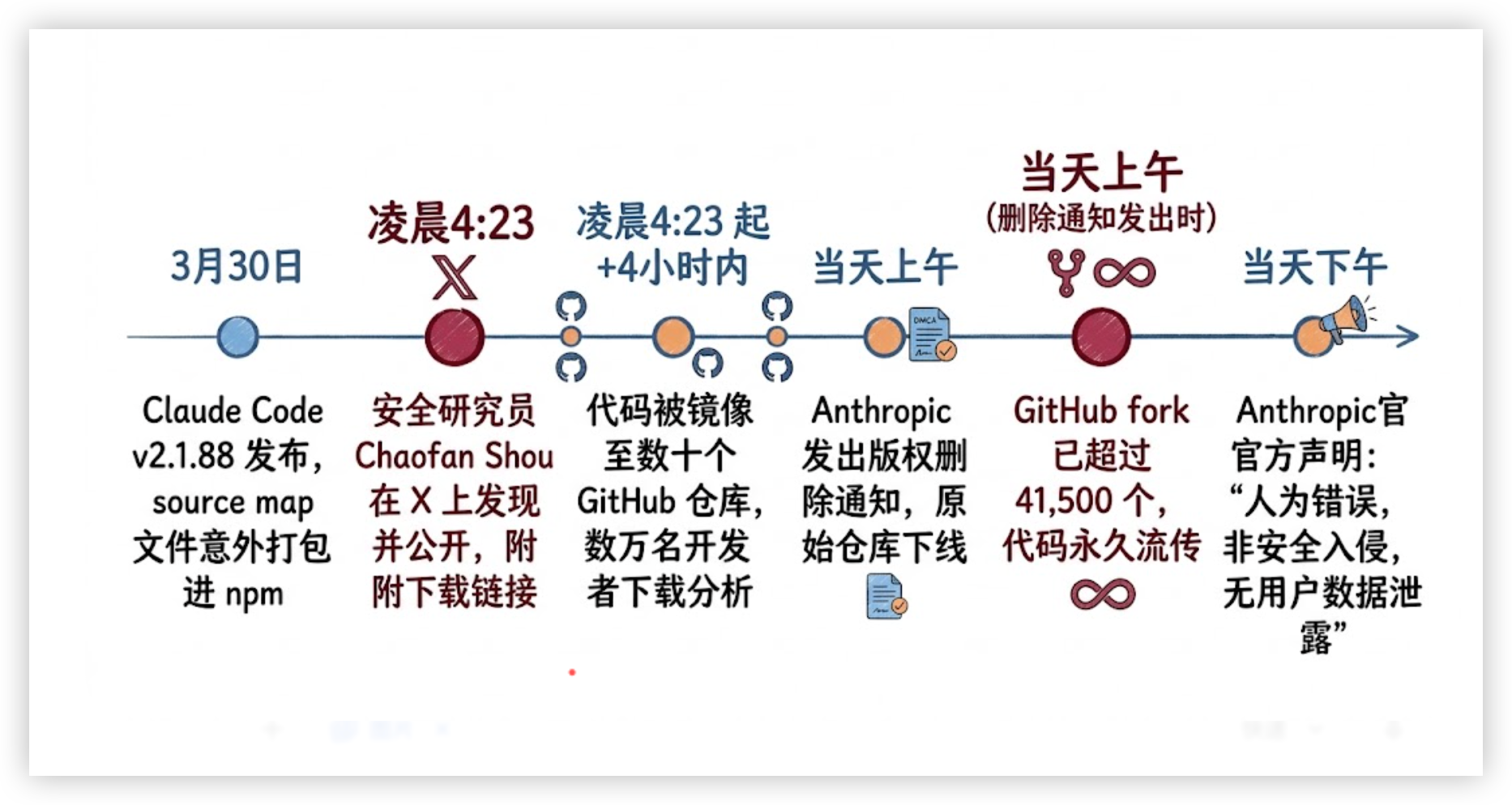
- 就在昨天凌晨,一个被遗忘的调试文件悄悄混进了发布包
- 4 小时内,2 万行源代码被全网镜像,GitHub fork 超过 4.1 万次
- 数十个未发布功能标志、内部模型代号、竞品梦寐以求的架构细节,全部曝光
- 这已经是 Anthropic 第二次犯同一类型的错误

你现在还觉得这是教科书案例吗?
它确实是——只不过是一本关于”当 AI 产品跑得足够快,哪些东西会第一个断裂”的教科书。
接下来,我想从事件本身、竞品影响、Anthropic PM决策复盘,以及对我们自己产品的启示四个维度,把这件事拆透。
一、一个被遗忘的文件,点燃了什么?
先把事实说清楚,因为很多报道把它讲得很神秘。
真相比任何阴谋论都更令人不安——因为它太普通了。
故事的主角,是一个 59.8MB 的 cli.js.map 文件。
你可以把 source map 理解成一本”翻译词典”:代码发布前会被压缩混淆,变成机器能读但人类看不懂的乱码;source map 的作用,是在出 bug 时把这些乱码翻译回原始的、人类能读懂的代码,方便工程师定位问题。这种文件在开发环境很有用,但就像公司的内部通讯录——有用,但绝对不该贴在门口。
Anthropic 的工程师在发布 Claude Code v2.1.88 时,忘记把这本”内部通讯录”从发布包里拿出来。
更要命的是,这个文件里藏着一个指向 Anthropic 内部存储桶的下载链接——完整的、注释齐全的 TypeScript 源代码,就放在那里,等着任何人来取。
剩下的事,你可以想象。
4 小时内,代码被镜像到数十个 GitHub 仓库,被数万名开发者分析、研究、传播。Anthropic 发出版权删除通知,原始上传者删除了仓库——但那时候,fork 已经超过 41,500 个。
Anthropic 的官方声明很快出来了:”这是一次由人为错误导致的发布打包问题,不是安全入侵。没有客户数据或凭证被暴露。”
声明没有问题。但它只回答了”发生了什么”,没有回答”这意味着什么”。
后者,才是产品经理需要思考的问题。
二、竞品拿到了地图,但最值钱的不在图上
让我们换一个视角——假设你是竞品的产品经理,拿到这份代码,你最兴奋的是什么?
发现一:Claude Code 的竞争力,原来不只是模型
行业里一直有个说法:”Claude Code 强,是因为 Claude 模型强。”
泄露的代码告诉你,这个说法只说对了一半。真正让 Claude Code 区别于”套壳终端”的,是它外面那层精心设计的工程框架。举几个具体的:
- 不走系统自带的搜索命令,而是专门造了一套搜索工具——通俗来说,就像普通厨师用菜刀切菜,Claude Code 专门配了一套日式刀具,每把刀都只做一件事,做得更准
- 集成了LSP语言服务协议——通俗来说,AI 不只是在”读文字”,它能理解”这个函数被哪些地方调用”,就像看一篇文章不只认识字,还理解了人物关系
- 把不变的内容和变化的内容分开存放——通俗来说,就像便利店把常温商品和冷藏商品分区,不用每次都全部重新整理一遍,省钱省时间
这些工程细节,国内竞品此前需要 2 年时间摸索。现在,一个下午就够了。
发现二:KAIROS——一个”永不下班的 AI 助理”
源码里有一个叫 KAIROS 的功能,出现了 150 多次,但从未对外发布过。
它的逻辑是:当你不在电脑前时,Claude Code 在后台自动运行,整理你的工作记忆,消除矛盾信息,把模糊的观察变成清晰的结论。
通俗来说,就像你有个助理,你下班之后她还在把今天的会议笔记整理归档,明天你来时桌上已经是整理好的工作台。这个功能现在所有竞品都知道了。
发现三:内部测试数据——包括 Anthropic 自己都没解决的问题
代码里有对即将发布新模型的内部测试数据:Capybara v8 的虚假声明率是 29-30%,相比 v4 的 16.7% 反而更高。
对竞品而言,这是黄金情报——他们现在知道 Anthropic 当前的”天花板”在哪,也知道攻哪个方向最有效。
那护城河在哪?作为 PM,你需要想清楚这件事。
很多人看完这次泄露,第一反应是”Anthropic 完了”。但这个判断跳过了一个关键问题:竞品拿到的是什么,没拿到的是什么?
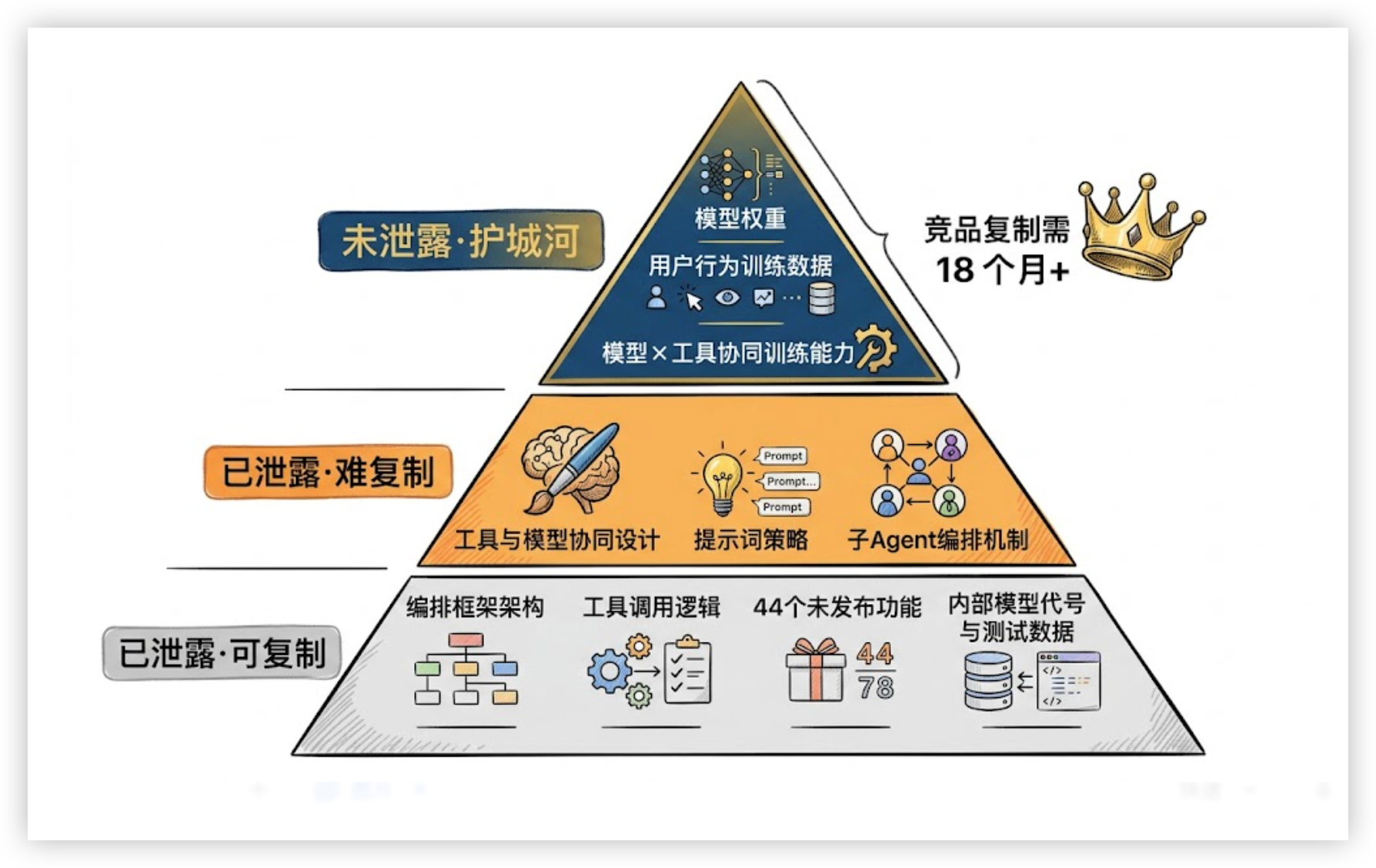
泄露的是”车架”,不是”发动机”。
竞品拿到了 Claude Code 的编排框架——架构怎么设计、工具怎么搭配、记忆怎么管理。但 Claude Code 真正的核心,是 Claude 模型与这套框架的协同训练。
打个比方:竞品拿到了一张米其林餐厅的厨房设计图,但那个能做出米其林菜品的厨师,还在 Anthropic 这里。厨房可以复制,厨师的手艺复制不了。
更难复制的是:Anthropic 有数百万开发者用户积累的真实行为数据,这些数据在持续优化模型的工具使用能力。这个飞轮,竞品今天开始转,18 个月后才能接近。
三、Anthropic 做对了一件事,但同一个坑踩了两次
这才是这篇文章最想聊的部分。
一家公司在危机中的决策,比危机本身更能说明它的产品哲学是否真的落地。
做对的事:在最关键的时刻,”保守”的产品哲学保住了信任
把时间倒回到 OpenClaw 爆火的 2026 年初。那时候,AI Agent 行业有两种产品哲学在打架。
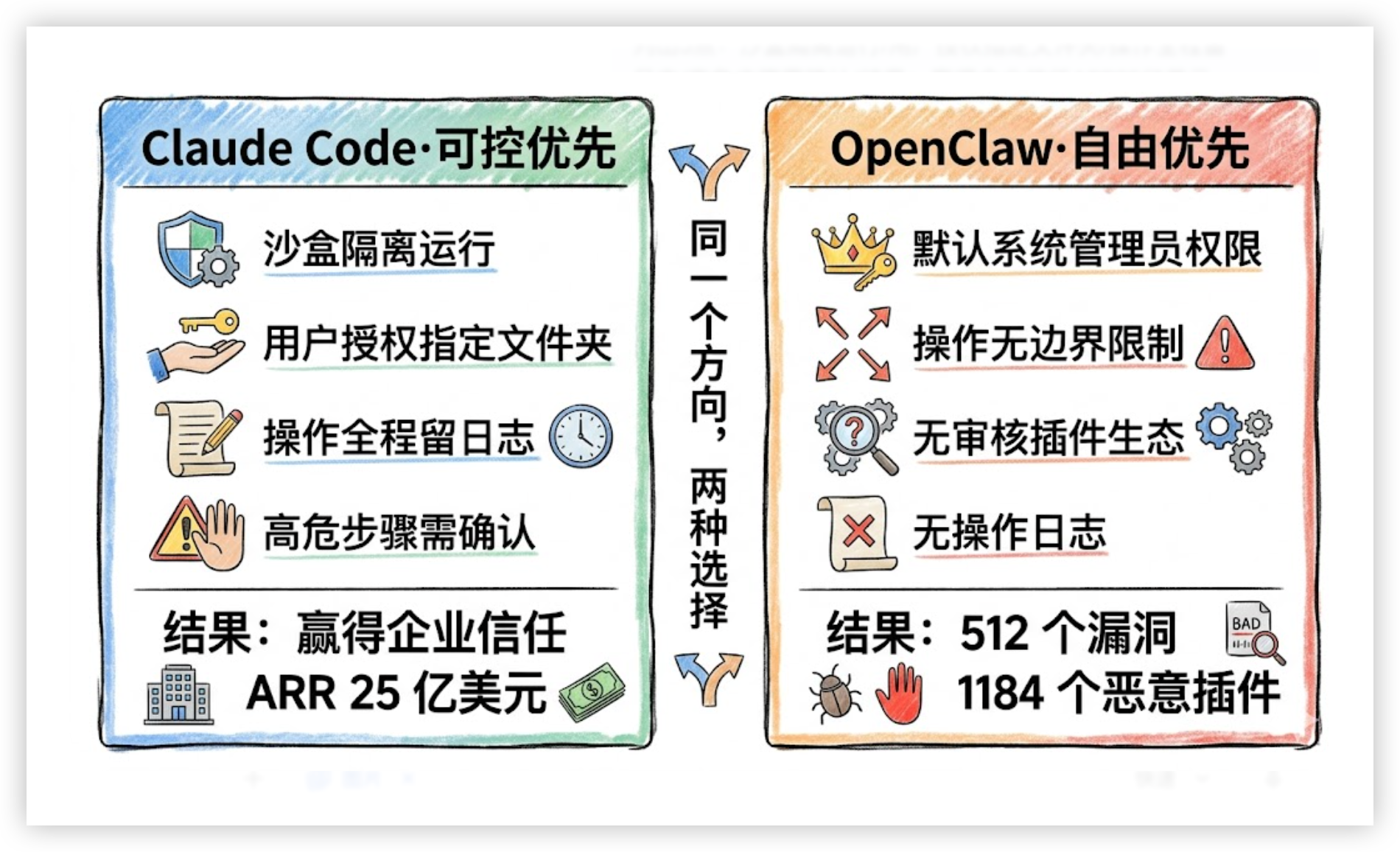
OpenClaw 选择了”自由优先”:直接给 AI 系统管理员级别的权限,能操作一切。通俗来说,这是把家里所有的钥匙都给了一个陌生的全能管家——强大、灵活,但如果这个管家被人操控了呢?
Claude Code 选择了”可控优先”:沙盒隔离,用户只授权指定文件夹,操作全程留日志,高危步骤要确认。这像是雇了一个专业助理,她只能在指定的办公桌上工作——安全、可控,但能力边界很清晰。
当时很多人觉得 Claude Code 太谨慎,增长不如 OpenClaw 那么惊艳。
但当 OpenClaw 陷入 512 个漏洞、1184 个恶意插件的安全危机,企业客户开始重新评估”我到底该信任哪款工具”时,Claude Code 的克制反而成了最大的差异化优势。
短期看,”可控优先”是劣势。长期看,”可控优先”是护城河。
这不是运气,是产品决策的提前量。如果你现在也在做 AI Agent 相关的产品,这个取舍值得你认真想一想。
没做好的事:第一次出了问题,只堵了漏洞,没修系统
2025 年 2 月,Claude Code 早期版本就发生过类似的源码泄露。
2026 年 3 月,同样的错误以几乎相同的方式再次发生。
这说明什么?不是工程师不够细心,而是第一次出了问题之后,团队修复了漏洞本身,但没有建立系统性的预防机制。
打个比方:家里漏水了,你找人补了那个洞,但没有去检查其他地方的管道是否有同样的隐患,也没有装一个漏水报警器。第二次漏水,只是时间问题。
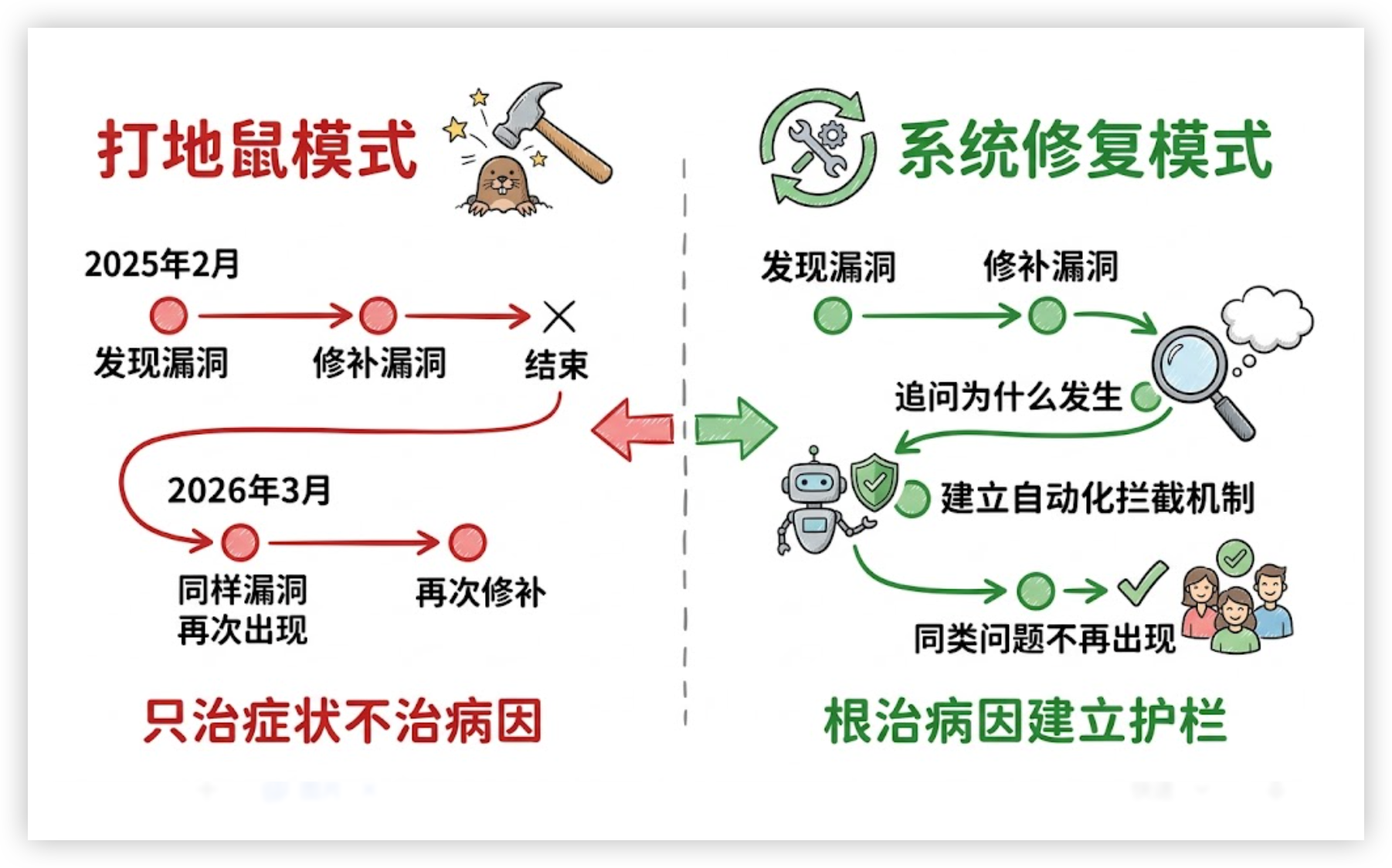
作为 PM,这里有一个需要内化的判断:
当同一类问题第二次出现,说明你解决的是症状,不是病因。
产品迭代速度越快,这个问题就越致命——因为你根本没有时间等第三次发生。
还有一步棋,现在还来得及走
代码已经无法从互联网上消失。在这种情况下,继续把 KAIROS、Capybara 当成”保密的未来规划”,其实意义不大了。
更聪明的做法,是把”被动泄露”转化为”主动发布”——在竞品完成仿制之前,抢先正式推出这些功能,把舆论焦点从”Anthropic 出了事故”,转移到”Anthropic 发布了重磅新功能”。
历史永远记得第一个正式推出的,不记得那个”仿制得很像”的。
四、如果这件事发生在你的产品上,你能拦住它吗?
这件事对我触动最深的,不是 Anthropic 有多惨,而是它印证了一件早就该说清楚的事:
AI 产品正在从”对话层”进入”执行层”。在这个跃迁中,产品的透明度,就是用户信任的全部来源。
对话式 AI 出了问题,最坏的结果是给了错误建议——用户关掉页面就算了。执行式 AI 出了问题,可能是删了文件,泄露了密钥,发出了不该发的消息。
通俗来说:以前 AI 是”只读”的,给了错误答案顶多误导你;现在 AI 是”读写”的,做了错误的操作会直接改变你的世界。
用户愿意把多少”执行权”交给 AI,取决于他们对产品有多信任。信任,是设计出来的,不是口号喊出来的。
这里有 6 个问题,是我从这次事件里提炼出来的,专门给正在做或即将做 AI Agent 产品的 PM:
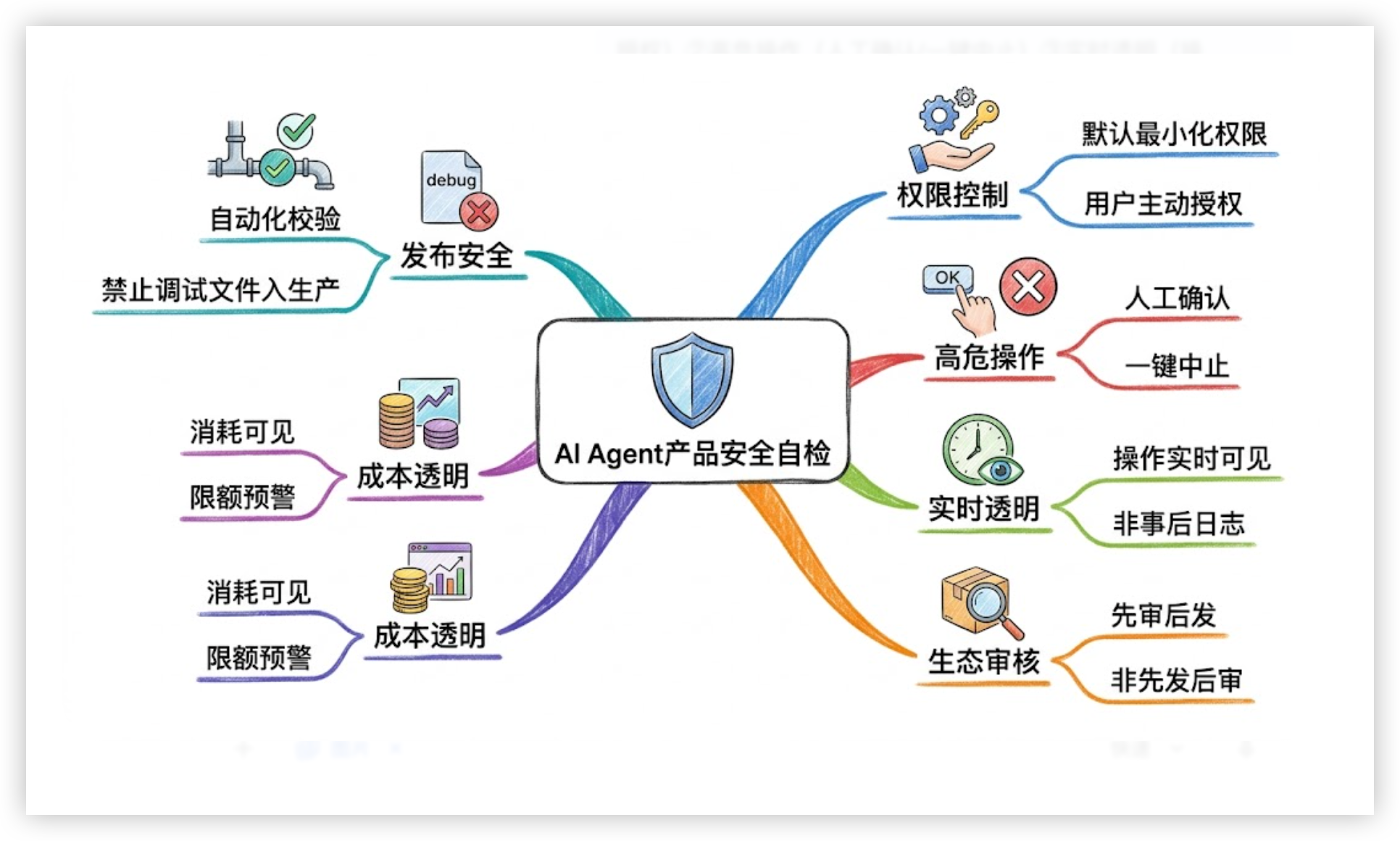
① 你的 AI 默认拿了多少权限? 用户第一次打开,AI 默认能访问什么?用户知道吗?Claude Code 的做法是:只拿完成任务所需的最小权限,用户必须主动授权每一项能力扩展。OpenClaw 的做法是:默认拿走所有权限,用户不知道。结果已经在那里了。
② 高危操作有没有人在回路? 删除文件、发送消息、调用外部接口——这些操作,用户在执行前有机会确认吗?还是 AI 自动完成,用户事后才知道?AI 犯错的成本,因为有没有”人工确认”这一步,差了不止一个量级。
③ 用户能不能实时知道AI在做什么? 不是事后查日志,是实时可见。Claude Code 在执行每一步操作时,都会展示它在做什么、为什么这么做。这不是炫技,是建立信任的基础设施。用户看不见的 AI,用户不会真正信任。
④ 第三方集成有没有安全审核? 你的产品支持插件或第三方工具接入吗?这些接入点,是”先发布后审核”还是”先审核后发布”?OpenClaw 技能市场里的 1184 个恶意插件,是”先发布后审核”模式交出的学费。
⑤ 成本对用户透明吗? AI Agent 的 Token 消耗往往难以预估。用户知道”这个任务大概要花多少钱”吗?有没有限额设置和实时预警?一款让用户收到天价账单才恍然大悟的产品,无论技术多先进,都不具备大众化的基础。
⑥ 你的发布流程,在检查”不该在生产包里的东西”吗? 这是这次事件专属的一条教训。Source map、内部调试信息、环境变量——这些东西,有没有在自动化发布流程里被拦截?不要等第二次事故发生了,再去补这道门。Anthropic 等了两次,你不需要。
结尾:中级 PM 和初级 PM,差的就是这一层
每个AI PM 看完这件事,都应该问的三个问题:
- 竞品能抄走什么,抄不走什么? 不是看表象,是找到真正难以复制的东西——那才是护城河。
- Anthropic 的决策里,哪些值得我学,哪些是我不能重蹈的? 从别人的危机里学习,比等自己出事便宜得多。
- 如果这件事发生在我的产品上,我的流程能拦住它吗? 把外部事件转化为内部自检,这才是读行业新闻的正确方式。
AI 执行层时代已经开始。用户愿意把越来越多的真实操作权交给 AI,但他们的信任是借出来的,不是给出去的。
泄露的是代码,泄不走的是信任——而信任,从来都是设计出来的,不是口号喊出来的。
这是 Claude Code 用 51.2 万行代码换来的教训。希望你不需要用自己的产品再验证一遍。
作者:山丘之上有AI
扫一扫 微信咨询

商务合作 联系我们
 微信扫一扫
微信扫一扫 



