

Claude Code+飞书CLI知识库迁移技巧!


每天在飞书里写文档、做协作,在 Obsidian 里沉淀笔记、构建知识图谱。两个平台之间一直隔着一道墙——现在,可以让 AI 自己把墙拆了。
一、AI 产品经理的知识焦虑
做 AI 产品经理有一个很实际的痛点:知识散落在太多地方了。
飞书是团队协作的主战场——PRD、会议纪要、竞品分析、项目文档,全在上面。但飞书的文档更像是”流水”,适合协作,不适合沉淀。你很难在飞书里回溯半年前的某个灵感,也很难把散落在不同知识库里的内容串联成知识图谱。
Obsidian 恰好相反。它是个人知识管理的利器,双向链接、标签体系、图谱视图,天然适合做深度的知识沉淀和关联。但它是本地工具,不擅长协作。

所以日常工作就变成了一个尴尬的循环:白天在飞书里产出文档 → 想要沉淀到 Obsidian → 需要手动一个个下载 → 格式还得重新整理 → 图片得单独保存 → 表格排版全乱了 → 算了,改天再说吧。
“改天再说”说了半年,知识库依然是两个互不相通的孤岛。
直到最近,我在折腾飞书 CLI 的时候,偶然发现了一条全新的路。
二、为什么飞书 CLI 是打通这一切的关键
在聊具体怎么做之前,得先说一个让我眼前一亮的东西:飞书开源的 CLI 工具。
CLI 是什么?30 秒讲清楚
你平时打开飞书 App,看到的界面——按钮、菜单、拖拽——这叫图形界面(GUI)。你得用眼睛看、用手去点,一步一步操作。
CLI 是另一种操作方式:你在一个黑色窗口里敲一行文字命令,电脑直接执行。 没有按钮,没有菜单,一行指令解决一个问题。
打个比方:GUI 像是你走到餐厅前台,看着菜单一道一道点;CLI 像是你直接给后厨发了一张纸条——”宫保鸡丁一份,少辣”——菜就做出来了。
对人类来说,GUI 显然更友好。但对 AI 来说,情况完全反过来——AI 根本不会“看”按钮和“点”菜单,它天生就是靠文字指令工作的。 CLI 就是 AI 操控软件的天然接口。
飞书 CLI 意味着什么
飞书把自己的 CLI 开源了,覆盖了日历、消息、文档、多维表格、邮件、会议等几乎所有功能,提供了 200 多个命令。
这意味着:你可以让 AI 通过终端,直接对飞书下指令——查日程、发消息、读文档、建表格,全部用文字命令完成,不需要打开飞书 App 点任何按钮。
而且飞书 CLI 专门为 AI 场景做了一层封装,提供了 19 个”AI Skills”。装上之后,你甚至不需要知道具体命令是什么。你用中文告诉 Claude”帮我看看今天有什么会”,Claude 会自动选择对应的 CLI 命令去执行。你负责说人话,AI 负责翻译成机器能懂的指令。
这件事的意义,后面会越来越清楚——正是因为有了这个 CLI,我才能让 Claude 直接把飞书知识库的文档批量爬到本地。
三、从零开始:安装配置全流程
下面是我实际走过一遍的完整安装流程,踩过的坑也一并标出来了。
环境准备
唯一的前置要求是电脑上有 Node.js。如果还没装,去Node.js官网下载LTS版本,安装过程一路默认即可。
安装三件套
打开终端(Mac 用 Terminal,Windows 用 PowerShell),依次执行三条命令:
① 安装 Claude Code,在终端输入:
npm install -g @anthropic-ai/claude-code
② 安装飞书 CLI,输入:
npm install -g @larksuite/cli
③ 安装 AI Skills(给 Claude 装上飞书“技能包”)
npx skills add larksuite/cli -y -g
第三步容易被忽略,但非常关键。没有这些 Skills,Claude 不知道飞书 CLI 有哪些命令可用,等于给了它一把钥匙但没告诉它锁在哪。
踩坑提醒:如果安装过程报网络错误,大概率是 npm 源的问题。执行 npm config set registry https://registry.npmmirror.com 切换到国内镜像后重试。
创建飞书应用
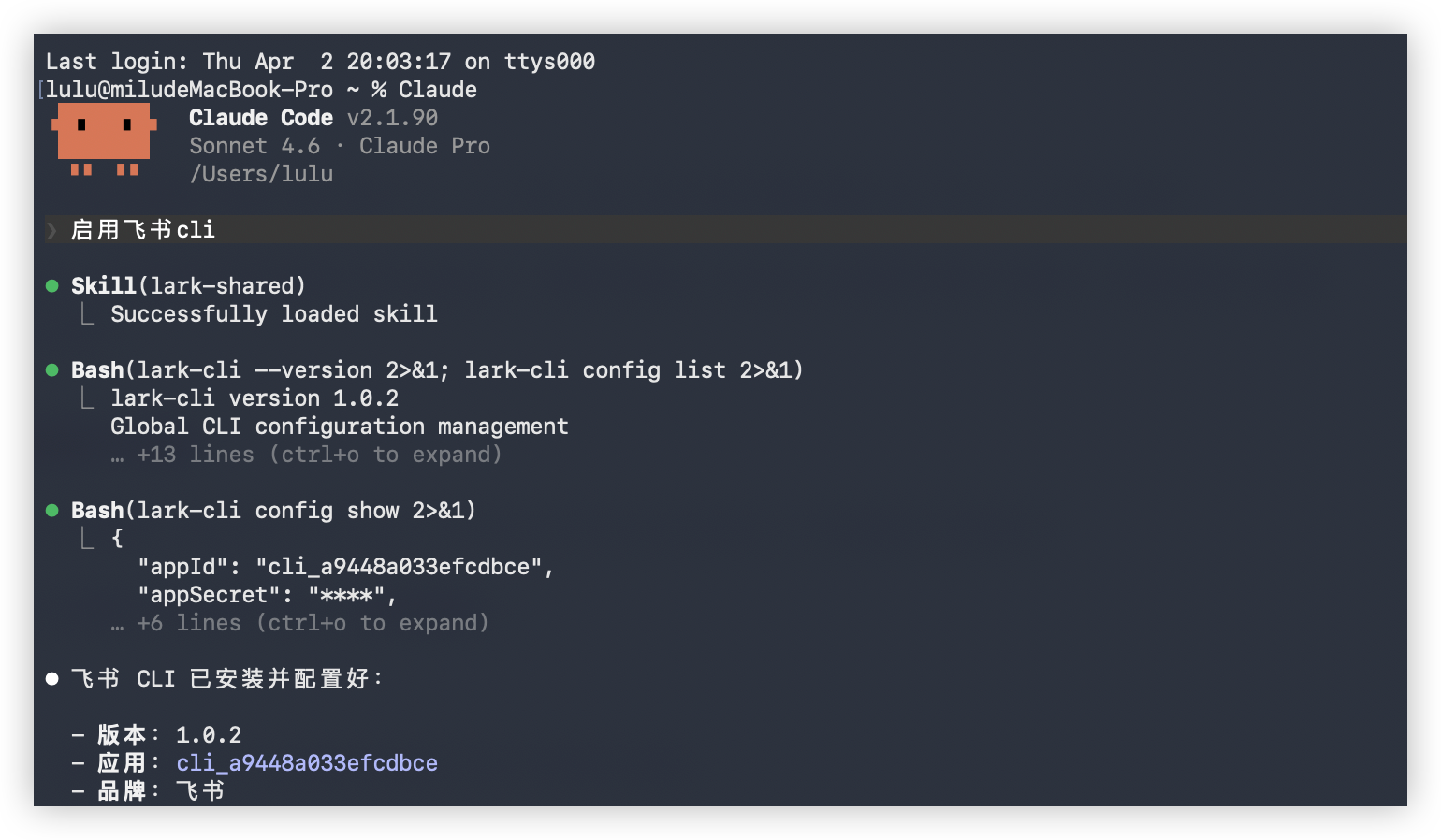
接下来需要在飞书开放平台创建一个”应用”——可以理解为给 AI 在飞书里注册了一个身份,后续所有操作都通过这个身份执行。
lark-cli config init –new
终端会弹出一个链接,打开后按提示创建应用:起个名字、选个头像、确认。创建完成后回到终端,配置会自动同步。
授权登录
lark-cli auth login –recommend
–recommend 会自动勾选常用权限,省得你逐个选。终端输出授权链接,打开后用飞书扫码完成授权。验证是否成功:
lark-cli auth status
能看到你的用户名和权限状态就说明全部就绪。
踩坑提醒:企业飞书用户可能会遇到”应用审批中”的提示,需要等管理员审批通过才能继续。个人版飞书一般没有这个问题。
最重要的一步:重启 Claude Code
安装完上面所有东西后,必须重启 Claude Code。不重启的话,Claude 感知不到新装的 Skills,你跟它说什么飞书相关的指令它都会一脸懵。
重启之后,直接用中文下达任务就可以了:
“帮我创建一下待办事项”
“给XXX发一条消息:中午吃什么”
“帮我创建一个多维表格,标题叫项目进度表”
Claude 会自动把你的自然语言翻译成飞书CLI 命令,执行前会让你确认一下——点”同意”就完事了。到这一步,飞书的”控制台”就算正式交给 AI 了。
四、进阶玩法:让 Claude 直接爬取飞书知识库
安装完成后,基本的日程查询、消息发送、文档创建都不在话下。但让我真正兴奋的,是接下来这个发现。
第一次尝试:翻车现场
我脑子里突然冒出一个想法:既然 Claude 可以通过CLI 操控飞书,那能不能直接让它把整个知识库的文档爬下来?
说干就干。我给了一个简单粗暴的指令:”帮我把飞书知识库的文档都下载下来”。
几分钟后,80 多个 .md 文件哗啦啦出现在我的本地文件夹里。
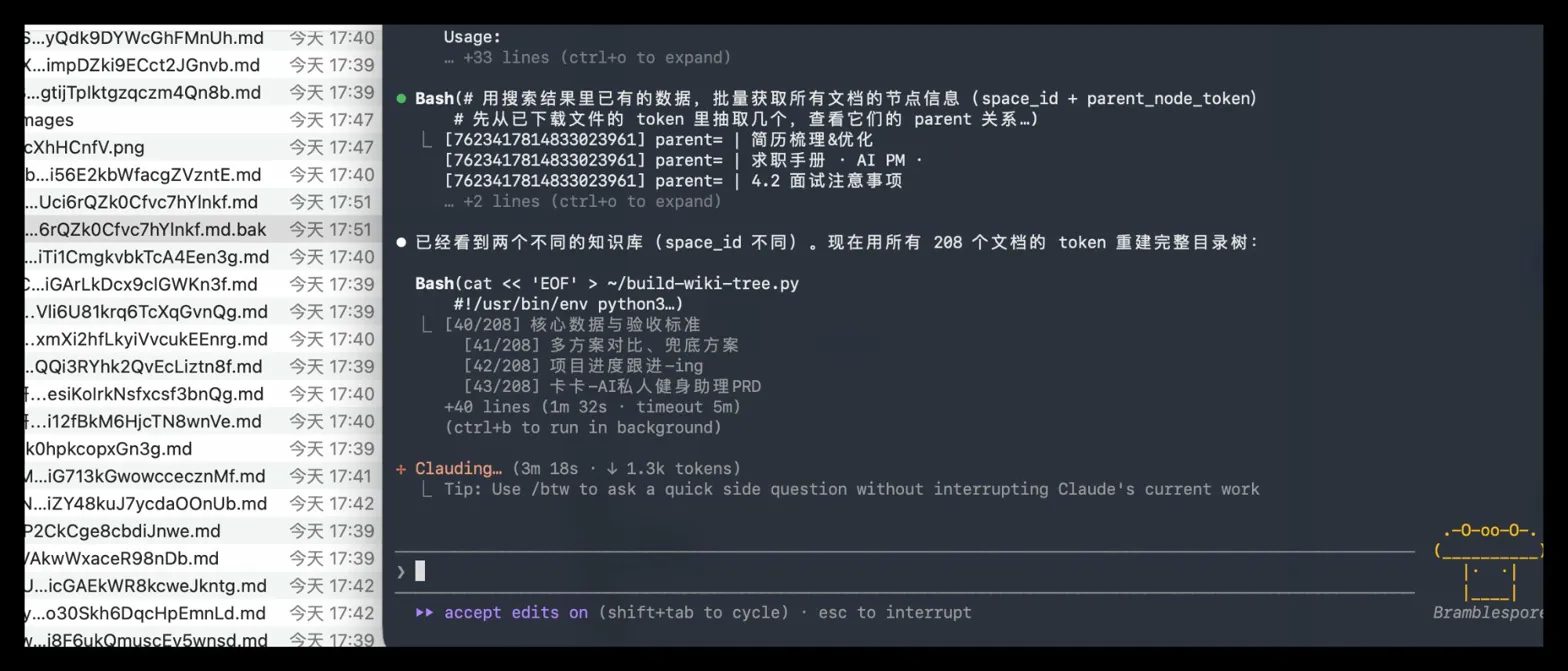
打开一看——一团乱麻。
所有文件平铺在同一个目录下,没有任何层级结构。文档里的图片全部丢失,只剩下空的引用链接。飞书里排版整齐的表格,变成了一堆无法解析的HTML标签。
踩坑复盘:三个关键问题
冷静下来分析,我意识到三个问题:
问题一:结构丢失。 飞书知识库是有层级的——知识库 → 父文档 → 子文档,但直接爬取会把所有文件拍平,丢失目录关系。而且 CLI 只能识别直属的知识库 ID,不会自动递归子文档。
问题二:图片不下载。 飞书文档里的图片是云端链接,导出 Markdown 时只保留了 URL 引用,不会自动下载图片到本地。一旦离开飞书环境,图片全部失效。
问题三:表格格式损坏。 飞书的表格导出后是 <lark-table> 自定义标签,不是标准的 Markdown 表格语法,需要额外转换。
解决方案:一个结构化的 Prompt
经过反复测试,我终于摸索出了一套完整的结构化 Prompt,能够一次性解决上面所有问题。这个 Prompt 你可以直接复制使用:
我想把飞书云文档按知识库分类批量下载到本地,要求如下:
1. 分类结构:按飞书知识库的层级结构(知识库→父文档→子文档)创建对应的文件夹,不要把所有文件平铺在一起
2. 表格处理:飞书导出的 <lark-table> 标签需转换为标准 Markdown 表格格式(| col | col |)
3. 图片处理:
– 有图片的文档,建一个以文档名命名的子文件夹,结构为 文档名/index.md + 文档名/images/
– 无图片的文档直接输出为 文档名.md
– 图片下载后替换 MD 中的引用为本地相对路径
4. 跳过规则:BITABLE(多维表格)和 SHEET(电子表格)类型跳过,只下载 DOCX/DOC 文档
5. 工具:使用 lark-cli,已安装并完成授权
6. 知识库范围:只下载以下知识库——[替换成你的知识库名称]
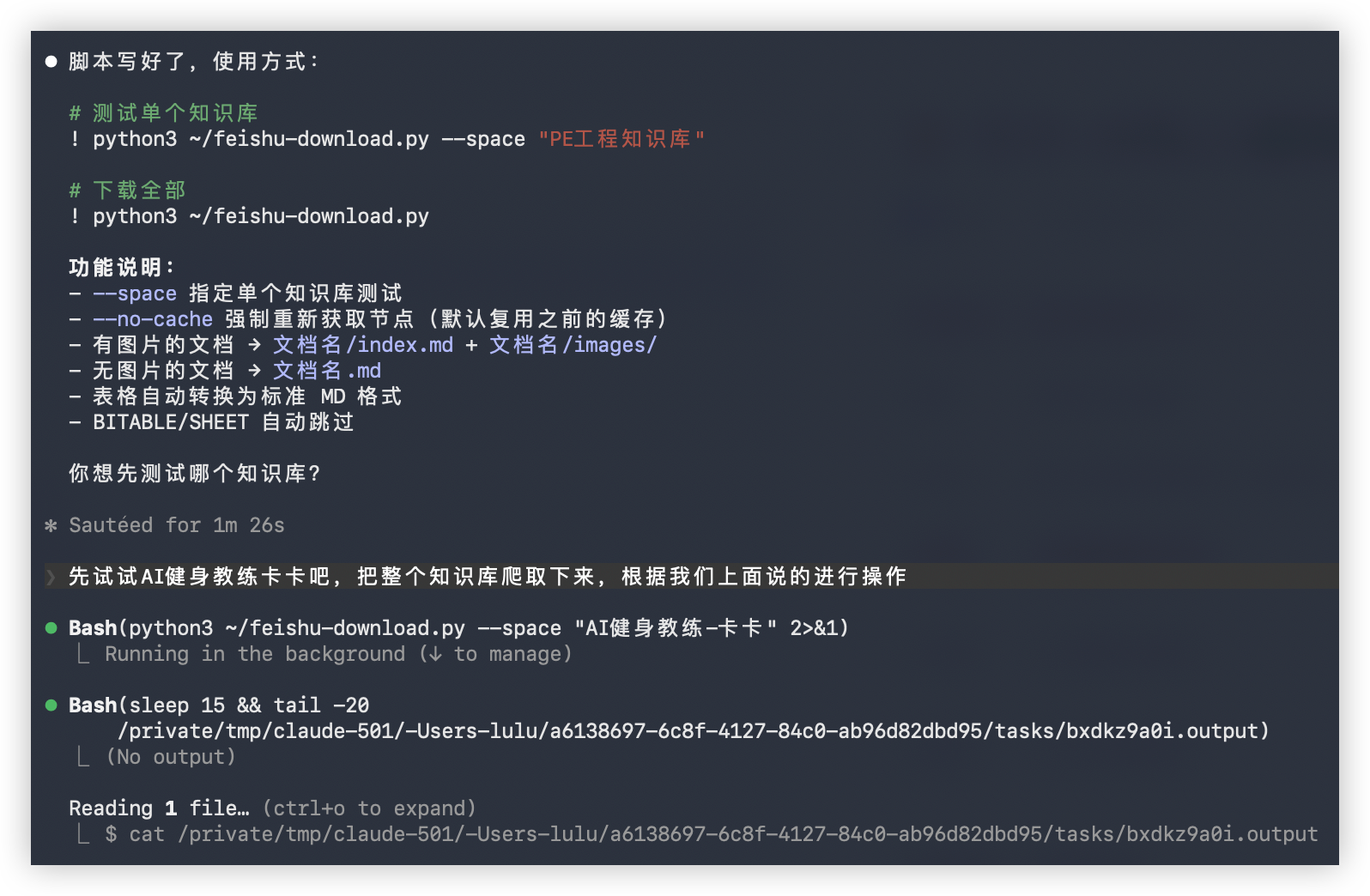
请先写脚本,支持 –space 参数指定单个知识库测试,确认效果后再全量下载。
效果:98 个文档,271 张图片,一键搞定
Claude 拿到这个 Prompt 后,先写了一个 feishu-download.py 脚本,支持 –space 参数指定单个知识库测试。我先拿”AI 健身教练-卡卡”这个知识库试水,确认效果没问题后,再全量下载。
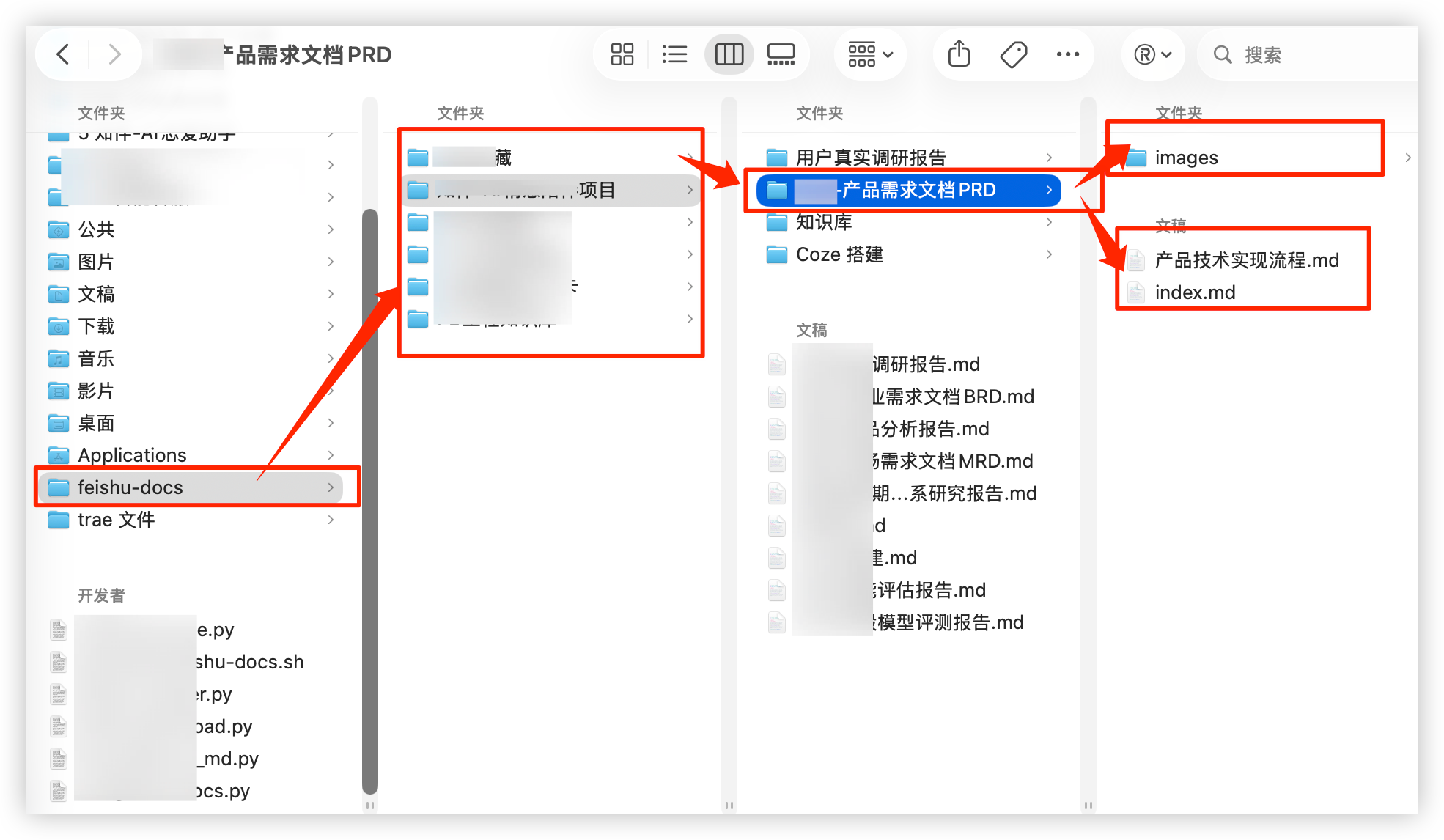
最终结果:
- 成功下载 98 个文档
- 跳过 12 个(BITABLE/SHEET 类型)
- 下载图片 271 张
- 全部按知识库 + 层级归类,图片在各自文档文件夹内
整个过程大约 5 分钟,完全自动化,零手动操作。
这个过程中 Claude 的工作链路是这样的:首先通过飞书 API 批量获取所有文档的节点信息,然后用这些信息重建完整的目录树(208 个文档),接着按照目录结构创建文件夹、下载文档内容、转换表格格式、下载并替换图片引用。
五、更大的图景:飞书 × Obsidian 双向赋能
下载到本地只是第一步。真正让我觉得”这条路走对了”的,是想清楚了两个平台各自该放什么、怎么联动、以及如何避免内容重复。
首先要解决的问题:不是搬运,是”翻译”
很多人第一反应是”把飞书文档全部同步到 Obsidian”,但这样做只会制造两份一模一样的内容,维护成本翻倍,还不如不同步。
正确的思路是:飞书的内容到了 Obsidian,要经过一次“翻译”——从协作态转化为知识态。
什么意思?举个例子。一篇飞书上的”Q2 竞品分析报告”,里面有大量协作过程中的讨论痕迹、待办事项、@某某同事的备注。这些在飞书里是有用的上下文,但搬到 Obsidian 就变成了噪音。
Claude 可以帮你做这个翻译:提取核心结论和洞察,去掉协作噪音,重新组织成适合个人知识体系的结构,再补上 Obsidian 的 frontmatter 元数据(tags、category、related),让它能和你已有的知识网络产生链接。
两个平台的边界:什么该放哪里
经过实践,我摸索出了一个清晰的分工原则——飞书放“过程”,Obsidian 放“结果”。
只留在飞书的内容:
- 日常会议纪要(协作上下文强,离开团队就失去意义)
- 进行中的项目文档(需要多人实时编辑)
- 即时沟通和审批流(天然属于飞书的领地)
- 多维表格和数据看板(飞书的强项,Obsidian 做不了)
只留在 Obsidian 的内容:
- 个人方法论和思维框架(比如你对 AI Agent 架构的理解)
- 读书笔记、学习记录、灵感捕捉
- 长期积累的知识卡片(概念定义、原理解析)
- 每日日记和复盘
需要“翻译”后从飞书迁移到 Obsidian 的内容:
- 已结项的 PRD → 提炼成产品方法论笔记
- 竞品分析报告 → 提炼成行业洞察卡片
- 技术方案文档 → 提炼成架构知识笔记
- 复盘文档 → 提炼成经验教训清单
关键词是”提炼”而不是”复制”。Claude 帮你做的不是 Ctrl+C / Ctrl+V,而是把一篇 3000 字的项目文档浓缩成一张 500 字的知识卡片,同时自动关联到 Obsidian 里已有的相关笔记。
Claude 在中间做的三件事
第一件:入库时做清洗和提炼。 飞书文档批量下载后,让 Claude 逐篇阅读,去掉协作噪音,提取核心内容,补上 Obsidian 的 frontmatter(tags、category、related、status),统一格式。这一步把”飞书文档”转化成了”Obsidian 笔记”。
第二件:建立知识图谱关联。 Claude 可以通读你整个 vault,识别笔记之间的语义关联,自动添加双向链接。比如它发现”AI 健身教练 PRD”里提到了”用户留存策略”,而你的 vault 里恰好有一篇”留存指标体系”的笔记,它就会在两篇之间建立 [[]] 链接。时间一长,你的知识图谱会从散点变成网络。
第三件:反哺工作产出。 这是最容易被忽略的一步,也是真正的”双向赋能”。当你在 Obsidian 里积累了足够多的知识笔记后,下次用 Claude Code 写飞书文档时,可以让它先读取 Obsidian 的知识库。比如你要写一份新的 PRD,Claude 可以调取你之前沉淀的竞品洞察、用户画像方法论、技术架构笔记,产出的内容会比从零开始写专业得多。
这就形成了一个正循环:飞书产出 → Claude 提炼入 Obsidian → 知识积累 → Claude 调取写飞书 → 更高质量的产出 → 继续提炼……
避免重复的增量同步策略
日常使用中,不需要每次都全量下载。我建议的节奏是:
- 周频同步: 每周花 5 分钟,让 Claude 增量下载本周飞书新增或修改的文档。它会自动识别哪些是新内容,只处理增量部分。
- 同步后立即分流: 下载完不要直接扔进 Obsidian 的正式目录。先放到一个”收件箱”文件夹(,让 Claude 做一轮筛选——哪些值得提炼入库,哪些只是过程性文档不需要保留。
- 保留溯源链接: 每篇从飞书迁移过来的 Obsidian 笔记,在 frontmatter 里加一个 source 字段,记录原始飞书文档的链接。这样你既不需要在两边保留完整内容,又能随时溯源到飞书原文查看完整的协作上下文。
- 定期清理: 每月让 Claude 扫一遍 Obsidian vault,识别内容高度重复的笔记(比如同一份 PRD 被导入了两次),合并或删除冗余。
六、写在最后:AI 产品经理的工具观
这次折腾给我最大的启发不是某个具体的技术方案,而是一个思维方式的转变:
不是工具多就好,而是工具之间能不能用 AI 串起来。
过去我们评价一个工具好不好用,看的是它自身的功能有多强。但在 AI Agent 的时代,评价标准变了——一个工具好不好用,取决于它有没有给 AI 留接口。
飞书做对了一件事:它把 CLI 开源了,给 AI 留了一个”控制台”。这意味着飞书不再只是一个人类用的协作工具,它同时也是一个 AI 可以操控的基础设施。
这个趋势会越来越明显。未来的 SaaS 工具竞争,不只是比谁的 GUI 好看、功能多,更是比谁的 API 和 CLI 对 AI 更友好。因为在 AI Agent 的世界里,能被 AI 调用的工具,才是有生命力的工具。
对于 AI 产品经理来说,现在是一个非常好的时间点去建立自己的”AI + 工具链”工作流。不需要会写代码,你只需要学会和 AI 对话,告诉它你想要什么,剩下的交给它。
操作不懂的可以评论区提问~
作者:山丘之上有AI
扫一扫 微信咨询

商务合作 联系我们
 微信扫一扫
微信扫一扫




